The GenAI Maturity Model
Is your AI Enterprise-ready ?
As we look across hundreds of projects, customers and partners we are seeing some distinctive growth and maturity trends . The maturity model for Generative AI reflects this and outlines a framework, delineating the progressive advancement of GenAI solutions across seven distinct levels of sophistication.
Using such a Maturity Model, organizations can gain a clear understanding of their current position on the GenAI maturity model and develop a targeted strategy to advance their capabilities and achieve their business objectives. This assessment also helps them make informed decisions about technology investments, talent acquisition, and process optimization, ensuring a more successful and business capability- aligned GenAI journey.
The GenAI Journey
The Gen AI Maturity Model : Levels of Sophistication
Level 0: Prepare Data
Level 1: Select Model & Prompt: Serve Models
Level 2: Retrieval Augmentation: Retrieve Info to Augment the Prompt
Level 2.1: Simple Retrieval and Generation
Level 2.2: Contextual Retrieval and Generation
Level 2.3: Dynamic Retrieval and Generation
Level 2.4: Multi-Source Retrieval and Generation
Level 2.5: Knowledge-Aware Generation
Level 3: Tuning the Model with Domain Specific Data
3.1. In-Context Learning (ICL)
3.2. Multi-shot (Using Large Context Windows)
3.3. Pretraining Small Language Models
3.4. Adaptor Tuning
3.5. Low-Rank Adaptation (LoRA)
3.6. Other Parameter-Efficient Fine-Tuning Methods
3.7. Domain-Specific Pretraining
3.8. Supervised Fine-Tuning
3.9. Full Fine-Tuning
3.10. Instruction Tuning
3.11. Reinforcement Learning with Human Feedback (RLHF)
3.12. Direct Preference Optimization (DPO)
3.13. Multitask Fine-Tuning
3.14. Meta-Learning (Learning to Learn)
3.15. Active Learning
3.16. Knowledge Distillation
Level 4: Ground the Model Output with Search & Citations
Level 5: Agent-based Systems
Agent-Based vs. Multi-Agent Systems
Level 6: The Multi-Agent Multiplier
Horizontal and Vertical Domains
Leveraging GenAI to Increase ROI in Horizontal Domains
Leveraging GenAI to Increase ROI in Vertical Domains
Conclusion and Call to Action
References
Note that the GenAI Reference Architecture details the technical aspects of these components at each level of maturity.
In order to align skills and internal capabilities with desired business outcomes, enterprises and organizations can realistically assess their current position on the GenAI maturity model , then look at the business outcomes they want to achieve and gauge what it would take to get there — their future maturity state — technically, and thus realistically align their initiatives, skills development, enablement and build or buy decisions with. the level of maturity that would help them transform to realize their desired business outcomes.
You can approach such an assessment as follows:
- Identify Key Business Outcomes: Organizations should begin by clearly defining the specific business outcomes they aim to achieve through GenAI implementation and and KPIs used to measure them. These outcomes could range from improving customer service and automating processes to enhancing decision-making or developing new products and services.
2. Map Outcomes to Maturity Levels: Once the desired outcomes and KPIs are identified, organizations can map them to the corresponding levels in the maturity model. For example:
- Level 0: If the primary goal or capability is to collect and organize data for future GenAI initiatives, the organization is likely at Level 0. data of course is the foundational element that fuels AI; whether predictive AI or generative AI.
- Level 1 & 2: If the focus is on using GenAI for basic tasks like content generation , summarizing content, question answering using the base capability and knowledge of the foundation model being served or to information retrieval, the organization might be at Levels 1 or 2.
- Level 3 & 4: Organizations looking to customize GenAI models with their data or ensure the quality and relevance of outputs are likely at Levels 3 or 4.
- Level 5 & 6: For complex use cases requiring multi-agent systems, advanced reasoning, or responsible AI practices, organizations might be aiming for Levels 5 or 6.
3. Assess Current Capabilities: Organizations should then assess their current capabilities in terms of data infrastructure, model selection, prompt engineering, model tuning, evaluation, and infrastructure for multi-agent systems. This assessment can be done through internal audits, external consultations, or benchmarking against industry standards.
4. Identify Gaps and Opportunities: By comparing their desired outcomes with their current capabilities, organizations can identify gaps in their GenAI maturity. These gaps represent areas where investment and development are needed to reach the desired level. Additionally, they might discover opportunities to leverage existing strengths and accelerate their progress.
5. Develop a Roadmap: Based on the assessment, organizations can create a roadmap outlining the steps required to bridge the gaps and achieve their desired business outcomes. This roadmap should prioritize initiatives that align with the strategic goals and allocate resources effectively. See the GenAI Roadmap for guidance on Strategy & ROI and Roadmap parts one and two. Also to know which detailed components to omplement as you drive higher levels of maturity check out the GenAI Reference Architecture.
The GenAI Journey
Yes, GenAI augments Data Strategy, Pipelines, Sharing, etc. and Predictive AI in the implementation of end to end applications. GenAI is a journey. This begins with the fundamental Level 0, where the focus is on procuring or generating, curating, and preparing data, the essential raw material for GenAI models. This involves gathering vast datasets, cleaning them, and ensuring their quality and relevance for training purposes.
Moving on to Level 1, organizations select appropriate GenAI models and craft effective prompts to interact with them. Prompts are textual inputs that guide the model’s output, and selecting the right model and prompt is crucial for achieving desired results. Additionally, this level involves serving these models, making them accessible for specific tasks.
As we reach Level 2, the complexity increases with the retrieval of information through the GenAI model. This indicates a more sophisticated interaction, where the model is queried to extract specific insights or data from its vast knowledge base. Level 3 involves fine-tuning the GenAI model with proprietary or domain-specific data. Fine-tuning is a process that adapts a pre-trained model to a particular task or domain, enhancing its performance and customization. This enables organizations to tailor the model to their unique needs and requirements.
In subsequent levels, the model is further refined through grounding and evaluation of outputs, ensuring their accuracy, relevance, and ethical alignment. Multi-agent systems are introduced, where multiple GenAI models collaborate under the orchestration of a LLM. This facilitates complex tasks requiring coordination and the integration of diverse capabilities. Observability and LLMOps become paramount, ensuring transparency in model behavior and streamlining the operational aspects of the GenAI lifecycle.
Note that at higher levels of maturity, advanced techniques like Tree-of-Thought (ToT) [16], Graph-of-Thought (GoT) [17], DSPy [18], self-correction [19], and ReAct [20] can be employed to enhance the reasoning, planning, and action abilities of GenAI models. These techniques enable sophisticated decision-making and problem-solving capabilities, pushing the boundaries of what generative AI can achieve.
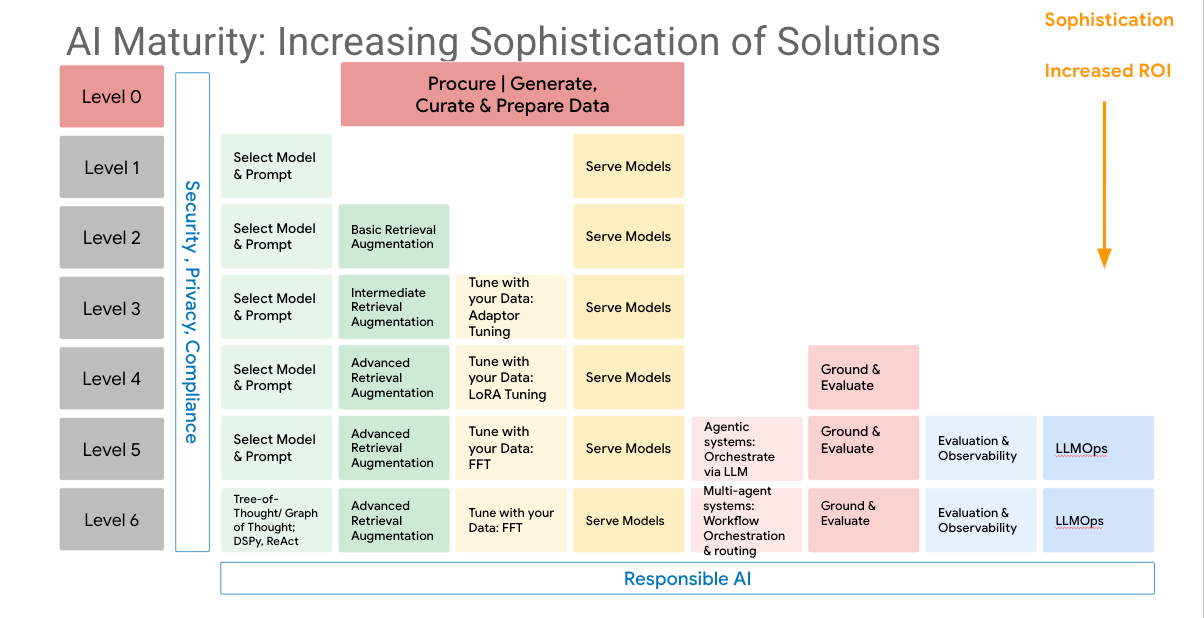
The maturity model diagram illustrates the increasing sophistication of Generative AI solutions across seven levels of maturity and sohistication.
Note that beyond the levels (rows) you can think of the components of the maturity level as clustered in columns that support increasing sophistication in that particular domain, for example, RAG or Modeling Tuning.
Let’s break each of the levels of maturity in GenAI into their constituent elements. Again, please refer to the GenAI Reference Architecture for a more in-depth discussion of each component.
The Gen AI Maturity Model : Levels of Sophistication
This maturity model charts a path of increasing sophistication for GenAI solutions, starting with basic data preparation and model selection, progressing to fine-tuning, evaluation, and eventually reaching a stage of multi-agent systems, advanced reasoning, and responsible AI practices.
Level 0: Prepare Data
This foundational level focuses on acquiring or creating the necessary datasets and ensuring their quality and suitability for GenAI /LLM-based or Agent-based applications. This would involve procurement, cleansing, preparing, obtaining licenses to use, generating synthetic data and and data engineering and transformation activities.
Level 1: Select Model & Prompt: Serve Models
This is the simplest level: pick a LLM and prompt it. Organizations at this level have identified suitable models and are crafting effective prompts to interact with them. They are also capable of using these models for specific tasks that are often steered through pormpt engineering. Note that the same prompt may not yield favorable results for different LLMs.
Model Selection, Prompt Engineering, and Retrieval: The process begins with selecting a suitable LLM model based on the specific task and fine-tuning it with proprietary data. Effective prompt engineering guides the model’s behavior, and information retrieval mechanisms extract relevant information from internal knowledge bases. This retrieval step, often powered by enterprise search capabilities, allows the model to access relevant documents and data within the organization’s internal resources.
Note that in-context learning and multi-shot learning can provide promising model tuning. See the section model tuning.
Level 2: Retrieval Augmentation: Retrieve Info to Augment the Prompt
Building upon the previous level, this stage involves retrieving relevant information through the GenAI model. This indicates a more sophisticated interaction with the model to extract specific insights or data.
Here, the focus shifts to fine-tuning the GenAI model with proprietary or domain-specific data. This allows for improved performance and greater customization of the model to meet specific requirements.
Retrieval Augmented Generation (RAG) is a framework that combines information retrieval systems with LLMs to generate more accurate and informed responses. The sophistication of RAG can be categorized into different levels based on the complexity of retrieval and integration mechanisms.
RAG (Retrieval-Augmented Generation): After the initial retrieval from internal sources, RAG leverages external Google-like search capabilities, such as those provided by Vertex AI grounding services. This involves querying external knowledge bases, the web, and other relevant sources to gather additional information that can enhance the accuracy and context of the generated output. The combination of internal and external search ensures a comprehensive understanding of the topic.
It’s important to note that Retrieval Augmentation has itself several layers of sophistication. Let’s explore them.
Level 2.1: Simple Retrieval and Generation
At this basic level, RAG retrieves relevant documents or passages from a knowledge base or corpus based on a user’s query. The retrieved information is then directly passed to the LLM, which generates a response using the retrieved content as context. This approach is relatively straightforward but may not always produce the most accurate or relevant results, as it relies solely on the LLM’s ability to understand and synthesize the retrieved information.
Level 2.2: Contextual Retrieval and Generation
This level introduces more sophisticated retrieval mechanisms that consider the context of the user’s query. Instead of simply retrieving documents based on keyword matching, it might utilize techniques like semantic search or query expansion to identify more relevant information. Additionally, the retrieved information could be filtered or ranked based on relevance or importance before being passed to the LLM. This improves the quality of the generated response by providing the LLM with more focused and contextually relevant information.
Level 2.3: Dynamic Retrieval and Generation
This level takes RAG a step further by dynamically retrieving information during the generation process. Instead of retrieving all relevant information upfront, the LLM can iteratively request additional information as needed to generate a more comprehensive and accurate response. This approach allows for more nuanced and interactive conversations, where the LLM can actively seek out additional information to clarify ambiguities or fill in knowledge gaps.
Level 2.4: Multi-Source Retrieval and Generation
This advanced level involves retrieving information from multiple sources, such as different knowledge bases, databases, or even real-time data streams. The challenge here is to effectively integrate information from diverse sources, which may have different formats, structures, or levels of reliability. This requires sophisticated retrieval and fusion techniques to ensure that the generated response is coherent, accurate, and up-to-date.
Level 2.5: Knowledge-Aware Generation
At this highest level of sophistication, RAG incorporates knowledge graphs or other structured knowledge representations to enhance the LLM’s understanding of the retrieved information. This allows the LLM to reason over the retrieved knowledge, identify relationships between concepts, and generate more informed and insightful responses. This approach is particularly useful for complex tasks that require deep domain knowledge or reasoning capabilities.
Level 3: Tuning the Model with Domain Specific Data
This level comprises the ability to tune the model, using either parameter-efficient fine-tuning, reinforcement learning with human feedback (RLHF), supervised fine tuning (SFT)or full fine-tuning (FFT) as the level of maturity increases .
See how you can use Google Vertex AI to tune your models in a spectrum of options .
This allows, the model to be trained on the data pertaining to that particular industry or domain. The secret source of every organization is their private data that they have accumulated over years of running the business and often represents unique value in that vertical domain. It is important to train models or two models that are conversed with the terminology, ontology entities, and the general knowledge encapsulated within the data of that particular vertical domain such as retail, healthcare, financial services, etc.
Fine-tuning AI models involves various methods that range in complexity and application, from simple context adjustments to advanced reinforcement learning. Here’s a detailed overview of these methods, arranged by levels of maturity and sophistication:
3.1. In-Context Learning (ICL)
- Maturity Level: Basic
- Relative Cost: Low
- Data Size Needed: Minimal (Zero-shot or few-shot examples)
- Description: The model makes predictions solely based on the context provided within the prompt, without updating its parameters. It relies on the knowledge acquired during its pre-training phase [1].
- Use Case: Quick and efficient generation of text or other outputs based on a given example or prompt. Ideal for scenarios where rapid adaptation is needed without retraining the entire model.
3.2. Multi-shot (Using Large Context Windows)
- Maturity Level: Intermediate
- Relative Cost: Moderate
- Data Size Needed: Minimal to Moderate (Few-shot to Many-shot examples with extensive context)
- Description: This approach builds upon standard In-Context Learning by leveraging very large context windows. It enables the model to process a significantly larger amount of information from the prompt and surrounding text. This not only improves the understanding of complex tasks but also allows for Multi-Shot In-Context Learning, where the model can learn from multiple examples provided within the context window.[15]
- Use Case: Ideal for tasks requiring deep contextual understanding, such as:
- Long-form text generation
- Complex question answering
- Document summarization
- Multi-step reasoning tasks
- Tasks where multiple examples can guide the model’s output
DeepMind’s research on “Many-Shot In-Context Learning” has shown significant performance gains when increasing the number of examples provided within the context window. This highlights the potential of utilizing large context windows not just for improved understanding but also for enabling the model to learn effectively from multiple demonstrations.
3.3. Pretraining Small Language Models
- Maturity Level: Intermediate
- Relative Cost: Moderate
- Data Size Needed: Moderate to Large (Depends on the model size and desired performance)
- Description: This involves training smaller language models from scratch or on a limited amount of data. These models are often used for specific applications where large, general-purpose models are impractical due to computational constraints or domain-specific requirements [3].
- Use Case: Effective for tasks in specialized domains with specific vocabulary or limited computational resources. Can also be used as a foundation for further fine-tuning or adaptation.
3.4. Adaptor Tuning
- Maturity Level: Intermediate
- Relative Cost: Low to Moderate
- Data Size Needed: Small to Moderate (Task-specific data)
- Description: This technique introduces small, trainable adapter modules into a pre-trained language model. These modules are specifically designed to be fine-tuned on new tasks while keeping most of the original model parameters frozen. This results in efficient task-specific adaptations with minimal computational overhead [4].
- Use Case: Ideal for adapting large models to specific tasks with limited resources. Maintains the efficiency and knowledge of the original model while allowing for quick and targeted fine-tuning.
3.5. Low-Rank Adaptation (LoRA)
- Maturity Level: Intermediate to Advanced
- Relative Cost: Moderate
- Data Size Needed: Small to Moderate (Task-specific data)
- Description: LoRA fine-tunes a model by adjusting a low-rank approximation of its weight matrices. This dramatically reduces the number of trainable parameters, making it much more efficient than full fine-tuning [5].
- Use Case: Effective for various tasks, including natural language processing and computer vision, where you need to adapt a large model to a specific task without incurring the full computational cost of training all parameters.
3.6. Other Parameter-Efficient Fine-Tuning Methods
- Maturity Level: Intermediate to Advanced
- Relative Cost: Moderate
- Data Size Needed: Small to Moderate (Task-specific data)
- Description: This category includes several techniques like prefix-tuning, prompt-tuning, and bitfit. They all aim to fine-tune a model by adjusting only a small subset of its parameters or inputs, significantly reducing the computational burden [6].
- Use Case: Ideal for quick adaptations to new tasks or scenarios where computational resources are limited. These methods offer a balance between efficiency and the ability to tailor the model’s behavior.
3.7. Domain-Specific Pretraining
- Maturity Level: Advanced
- Relative Cost: High
- Data Size Needed: Large (Domain-specific corpus)
- Description: This involves pretraining a model on a large corpus of text specific to a particular domain (e.g., legal, medical, or financial). This helps the model capture the nuances, vocabulary, and knowledge structures unique to that domain [7].
- Use Case: Extremely valuable in specialized fields where general-purpose models may lack the necessary domain expertise. Can be used as a starting point for further fine-tuning or adaptation within that domain.
3.8. Supervised Fine-Tuning
- Maturity Level: Advanced
- Relative Cost: High
- Data Size Needed: Large (Labeled task-specific data)
- Description: This is the classic method of fine-tuning where the entire model is trained on a labeled dataset specific to a particular task. All model parameters are updated to optimize its performance on that task [8].
- Use Case: Highly effective for tasks with ample labeled data, such as text classification, sentiment analysis, named entity recognition, and question answering.
3.9. Full Fine-Tuning
- Maturity Level: Advanced
- Relative Cost: Very High
- Data Size Needed: Large to Very Large (Labeled task-specific data)
- Description: This method is the most extensive form of fine-tuning, where all parameters of the pre-trained model are adjusted during training on the new task-specific dataset [8].
- Use Case: Typically reserved for situations where maximum performance on a specific task is critical, and you have access to significant computational resources and a large, high-quality dataset.
3.10. Instruction Tuning
- Maturity Level: Advanced
- Relative Cost: High to Very High
- Data Size Needed: Large (Diverse, instruction-based dataset)
- Description: This approach involves fine-tuning models to follow a wide range of instructions and complete various tasks. The model is trained on diverse datasets containing instructions and their corresponding desired outputs [9].
- Use Case: Enhances the model’s ability to understand and execute complex instructions, making it suitable for general-purpose AI assistants, chatbots, and other applications where flexible task execution is required.
3.11. Reinforcement Learning with Human Feedback (RLHF)
- Maturity Level: Cutting-Edge
- Relative Cost: Very High
- Data Size Needed: Variable, but often Large (Human feedback data)
- Description: RLHF combines reinforcement learning techniques with feedback from human users. The model learns by receiving rewards or penalties based on its actions and the feedback it receives, aiming to optimize its behavior according to human preferences [10].
- Use Case: Applied in situations where human preferences are crucial, such as conversational agents, recommendation systems, and other applications that interact directly with users.
3.12. Direct Preference Optimization (DPO)
- Maturity Level: Experimental
- Relative Cost: Very High
- Data Size Needed: Variable (User preference data)
- Description: DPO focuses on directly optimizing a model based on user feedback and preferences. This often involves techniques like gradient descent to adjust the model’s parameters in alignment with observed user preferences [10].
- Use Case: Particularly suited for applications where user satisfaction is paramount, and preferences can be directly measured and optimized. Examples include personalized content recommendation systems and user interface design.
3.13. Multitask Fine-Tuning
- Maturity Level: Advanced
- Relative Cost: High to Very High
- Data Size Needed: Large (Labeled data for multiple tasks)
- Description: In multitask fine-tuning, a model is trained on multiple related tasks simultaneously. This allows the model to leverage shared knowledge and representations across tasks, potentially leading to improved performance and generalization [11].
- Use Case: Beneficial in scenarios where a model needs to perform well on a diverse set of tasks, such as multi-domain customer service bots or models that need to understand various aspects of language (e.g., sentiment analysis, question answering, and text summarization).
3.14. Meta-Learning (Learning to Learn)
- Maturity Level: Cutting-Edge
- Relative Cost: Very High
- Data Size Needed: Variable, often Large (Meta-training data)
- Description: Meta-learning focuses on training models to quickly adapt to new tasks with minimal data. It involves training the model on a variety of tasks during the training phase, enabling it to learn how to learn efficiently [12].
- Use Case: Particularly relevant in situations where the model needs to rapidly adapt to new tasks or domains with limited examples, such as few-shot learning scenarios or personalized learning systems.
3.15. Active Learning
- Maturity Level: Advanced
- Relative Cost: High to Very High
- Data Size Needed: Variable, often Iterative (Initially small, growing as the model queries for more data)
- Description: Active learning involves the model actively selecting the most informative data points for labeling, thereby optimizing the fine-tuning process [13].
- Use Case: Extremely valuable in situations where labeling data is expensive or time-consuming. By focusing on the most relevant examples, active learning can significantly reduce the amount of labeled data needed for effective fine-tuning.
3.16. Knowledge Distillation
- Maturity Level: Intermediate to Advanced
- Relative Cost: Moderate to High
- Data Size Needed: Moderate to Large
- Description: Transferring knowledge from a large, pre-trained teacher model to a smaller, more efficient student model [14].
- Use Case: Useful for deploying models on resource-constrained devices while maintaining performance, such as mobile or edge devices.
Each of these methods represents a step up in complexity and resource requirements, from basic contextual adjustments to sophisticated techniques involving human feedback and extensive parameter adjustments. The choice of method depends on the specific requirements of the task, available resources, and desired performance outcomes.
Level 4: Ground the Model Output with Search & Citations
In addition to model fine-tuning, this level incorporates the grounding and evaluation of GenAI outputs. This means ensuring that the generated content is factually accurate, relevant, and aligned with ethical considerations.
At Level 4 of the GenAI maturity model, the combination of capabilities focuses on ensuring the quality and reliability of generated outputs through a robust grounding and evaluation process, enhanced by internal enterprise search and external Google-like search using Vertex AI grounding services.
Grounding and Evaluation: The retrieved information, both from internal and external sources, undergoes a thorough grounding and evaluation process. This includes verifying the accuracy of facts, identifying potential biases, and assessing the relevance of the information to the generated output. Vertex AI grounding services play a crucial role in this step by providing citations and references for the information used, adding credibility and transparency to the generated content.
- Post-RAG Refinement: After the grounding and evaluation process, the LLM may refine the generated output based on the feedback received. This refinement process ensures that the final output is not only accurate and relevant but also well-supported by credible sources.
- Serving Models: Finally, the refined and validated models are served to users or integrated into applications, providing reliable and informative responses that are grounded in verified information.
How Internal Enterprise Search and External Search with Google Vertex AI Grounding can Help Find Citations and References
Internal enterprise search helps by quickly identifying relevant documents, data, and information within the organization’s own knowledge repositories. This provides a valuable starting point for grounding the generated output in the context of the company’s specific knowledge and expertise.
External Google-like search, such as Vertex AI grounding services, expands the scope of information retrieval by accessing a vast array of external sources. This ensures that the generated output is not limited to the organization’s internal knowledge but also incorporates the latest information and insights from the broader domain.
When you combine these two search capabilities, the GenAI system can find citations and references from both internal and external sources, strengthening the credibility and reliability of the generated output. This post-RAG grounding and evaluation process ensures that the final output is not only informative but also trustworthy and transparent.
Level 5: Agent-based Systems
This advanced level introduces multi-agent systems, where multiple GenAI models work collaboratively under the orchestration of a central Large Language Model (LLM). This enables complex tasks requiring coordination and the integration of diverse capabilities. Additionally, there’s a strong emphasis on observability (monitoring and understanding model behavior) and LLMOps (operationalizing the GenAI model lifecycle).
At Level 5 of the GenAI maturity model, several key capabilities converge to form a sophisticated system that lays the groundwork for the evolution towards agent-based and multi-agent systems.
Model Selection, Prompt Engineering, and Retrieval: The process begins with selecting a suitable LLM model based on the specific task and fine-tuning it with proprietary data. Effective prompt [re-]engineering guides the model’s behavior, and information retrieval mechanisms extract relevant information from various sources, enriching the LLM’s knowledge base.You can use additional sophistication in prompt engineering such as In-context learning, Chain-of-thought, formatting with clear steps and XML -like structures or you can go further in sophistication and use outline-of-thought, tree-of-thought etc and combine that with ReAct frameworks that assess a result of the LLM and Reason about the observed output then regenerate and ultimately take action. So a level 5 sophistication is not only in the use of LLMOps and Agent-based Architecures but also can have deeper sophistication in advanced prompt engineering techniques.
Orchestration via LLM: One of the core innovations/ additions at Level 5 is the introduction of a central LLM as an orchestrator. This LLM acts as a conductor, coordinating the actions of other models or components. It assigns tasks, manages communication, and integrates outputs from different models, creating a cohesive workflow. This is the initial step towards agent-based systems, where individual models can be seen as agents with specialized roles.
Grounding and Evaluation: Carrying on from level 4, Grounding continues to be used to ensure the quality and reliability of the generated outputs, grounding mechanisms are employed. These mechanisms verify the information against reliable sources and assess the potential impact of responses. Evaluation processes monitor the system’s performance, providing feedback for continuous improvement.
Evaluation, Observability, and LLMOps: The introduction of formal and end to end observability and evaluation mechanisms for each component of the GenAI Reference Architecture is a key elment of level 5.
This continuous evaluation and monitoring of the system’s performance are essential to LLM generated content for various components of the architecture; the prompts, the RAG output, the Tuned Model drift or skew, the grounding output, etc. Observability provides insights into the LLM’s behavior, enabling proactive adjustments. LLMOps practices streamline the deployment, management, and monitoring of the entire GenAI infrastructure.
Agent-Based vs. Multi-Agent Systems
Let’s differentiate between these two concepts.
- Agent-based systems: Involve a single LLM model that acts as an agent, performing tasks, making decisions, and interacting with its environment. The LLM can be seen as a monolithic entity with various capabilities.
- Multi-agent systems: Evolve from agent-based systems by introducing multiple specialized LLMs. Each LLM acts as an independent agent with a specific role or expertise. These agents collaborate, communicate, and coordinate their actions to solve complex problems that a single agent cannot handle efficiently.
Level 5 serves as a stepping stone towards multi-agent systems by establishing the fundamental infrastructure for orchestrating multiple models. It enables organizations to experiment with assigning specific tasks to different models and evaluating their performance. This experimentation paves the way for the development of more sophisticated multi-agent systems, where diverse models with complementary skills can work together to achieve common goals.
Level 5 sets the stage for a paradigm shift from monolithic LLM models to a network of specialized agents, each contributing its unique strengths to tackle increasingly complex challenges. This transition promises to unlock new levels of efficiency, adaptability, and innovation in the field of GenAI.
Level 6: The Multi-Agent Multiplier
The pinnacle of maturity involves using advanced techniques like Tree-of-Thought or Graph-of-Thought to enhance the reasoning and planning abilities of GenAI models. These approaches facilitate more sophisticated decision-making and problem-solving. At this level, the LLM orchestrates and controls other LLMs, indicating a highly autonomous and capable GenAI ecosystem. The framework emphasizes Responsible AI, demonstrating a commitment to ethical and fair use of AI technologies.
Level 6 represents considerable GenAI maturity, seamlessly integrating advanced techniques and frameworks to achieve high-value capabilities.
- Enhanced Reasoning with Tree-of-Thought/Graph-of-Thought: Level 6 harnesses the power of Tree-of-Thought (ToT) or Graph-of-Thought (GoT) frameworks. These enable the LLM to break down complex problems into smaller, manageable steps, systematically exploring potential solutions and making informed decisions. This significantly enhances the reasoning, planning, and problem-solving abilities of the GenAI system.
- Active Information Gathering with DSPY and ReAct: Level 6 incorporates techniques like DSPY (Demonstrate-Search-Predict) and ReAct (Reasoning and Acting) approaches. DSPY guides the LLM in deciding when to search for external information, predicting relevant queries, and incorporating the retrieved information into its reasoning process. ReAct enables the LLM to actively interact with its environment, making decisions and taking actions based on the information it gathers.
- Information Retrieval and Integration: Level 6 utilizes advanced information retrieval techniques to access relevant data from various sources, including internal knowledge bases and external databases. The retrieved information is then seamlessly integrated into the LLM’s reasoning process, providing it with up-to-date and contextually relevant knowledge.
- Model Tuning with Custom Data: The LLM is fine-tuned with proprietary or domain-specific data to optimize its performance and tailor it to specific tasks and domains. This ensures that the model generates accurate, relevant, and contextually appropriate responses.
- Multi-Agent Orchestration and Control: Level 6 deploys a multi-agent system where multiple LLMs work collaboratively under the orchestration and control of a central LLM. This enables the system to handle complex tasks that require coordination, specialization, and diverse expertise.
- Grounding and Evaluation: Rigorous grounding and evaluation mechanisms are employed to ensure that the generated outputs are factually accurate, relevant, and aligned with ethical and safety guidelines. This involves verifying information against reliable sources and assessing the potential impact of responses.
- Evaluation, Observability, and LLMOps: Level 6 emphasizes continuous evaluation and monitoring of the GenAI system’s performance, providing insights into its behavior and enabling proactive adjustments. Robust LLMOps practices are implemented to streamline the deployment, management, and monitoring of the entire GenAI infrastructure.
Level 6 represents a harmonious integration of cutting-edge techniques and best practices, enabling the GenAI system to achieve unparalleled levels of reasoning, decision-making, and problem-solving capabilities. This comprehensive approach ensures that the system is not only powerful but also reliable, ethical, and adaptable to evolving requirements.
Horizontal and Vertical Domains
Next let’s take a look at how we can strategically implement GenAI across horizontal and vertical domains.
Here organizations can unlock significant ROI by improving efficiency, productivity, customer satisfaction, and innovation. For each of these metrics and KPIs are very important to identify early on, measure and monitor and correct. It is crucial to not only carefully define objectives, measure relevant KPIs, and but to continually adapt strategies to maximize the benefits of GenAI in the evolving and rapidly restructuring business landscape.
Leveraging GenAI to Increase ROI in Horizontal Domains
Of course, Horizontal domains refer to functions or processes that cut across various industries and business units within an organization. GenAI can be applied to these domains to enhance efficiency, productivity, and overall ROI.
- Marketing and Sales: Personalize customer experiences, generate targeted content, and optimize marketing campaigns, leading to increased customer engagement, conversion rates, and sales.
- Customer Service: GenAI-powered chatbots and virtual assistants can handle customer inquiries, automate responses, and resolve issues efficiently, improving customer satisfaction and reducing support costs.
- Human Resources: Streamline recruitment processes, personalize employee onboarding, and provide personalized learning and development opportunities, enhancing employee engagement and productivity.
- Finance and Accounting: Aautomate financial analysis, detect anomalies and fraud, and optimize financial processes, improving accuracy, efficiency, and risk management.
- Operations and Supply Chain: Optimize inventory management, predict demand, and streamline logistics, reducing costs and improving supply chain efficiency.
Leveraging GenAI to Increase ROI in Vertical Domains
And, Vertical domains are domain-specific or industry-specific areas that are particular to business domains and industries or even sub-industries, tailoring solutions to the unique needs and challenges of each sector.
GenAI can be deployed in various vertical domains to drive ROI.
- Healthcare: Assist in medical diagnosis, drug discovery, and personalized treatment plans, improving patient outcomes and reducing healthcare costs.
- Finance: Analyze financial data, predict market trends, and generate investment recommendations, enhancing decision-making and risk management.
- Retail: Personalize product recommendations, optimize pricing strategies, and enhance customer experiences, increasing sales and customer loyalty.
- Manufacturing: Optimize production processes, predict equipment failures, and enhance quality control, reducing costs and improving efficiency.
- Education: Personalize learning experiences, provide automated feedback, and create adaptive assessments, improving student outcomes and engagement.
Conclusion and Call to Action
It is important to understand the current level of maturity and sophistication of an organization, team project or even individual. Then we need to decide what the target level of maturity is in order to procure the skills develop the skills in order to achieve that level of sophistication that is necessary to fulfill the technical requirements that will provide the business impact and outcomes that have been defined at that target level of maturity..
Organizations can define and pave roadmaps to go from where they are to advancing their business objectives by building skills and capabilities using tools and leverage platforms such As Google Cloud AI that covers all levels of maturity to achieve the business outcomes at the target level of maturity that they aspire to be.
References
[1] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). [Language Models are Few-Shot Learners](https://arxiv.org/abs/2005.14165).
[2] Rae, J., Borgeaud, S., Cai, T., Millican, K., Young, A., Rutherford, E., Hutter, F., Laurenç, P., Humphreys, P., Hawkins, P., Winter, S., Eccles, T., Leike, J., Ring, R., Askell, A., Chen, A., Olsson, C., Welinder, P., McAleese, N., … Irving, G. (2021). [Scaling Language Models: Methods, Analysis & Insights from Training Gopher](https://arxiv.org/abs/2112.11446).
[3] Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108).
[4] Pfeiffer, J., Kamath, A., Rücklé, A., Cho, K., & Gurevych, I. (2020). [MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer](https://arxiv.org/abs/2005.00052).
[5] Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, S., Wang, L., Wang, L., & Chen, W. (2021). [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685).
[6] Li, X. L., & Liang, P. (2021). [Prefix-Tuning: Optimizing Continuous Prompts for Generation](https://arxiv.org/abs/2101.00190).
[7] Lee, J., Yoon, W., Kim, S., Kim, D., Kim, S., So, C. H., & Kang, J. (2019). [BioBERT: a pre-trained biomedical language representation model for biomedical text mining](https://arxiv.org/abs/1901.08746).
[8] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).
[9] Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Metzler, D., Chi, E., Hashimoto, T., Vinyals, O., Liang, P., Dean, J., & Fedus, W. (2021). [Finetuned Language Models Are Zero-Shot Learners](https://arxiv.org/abs/2109.01652).
[10] Christiano, P., Leike, J., Brown, T., Martic, M., Legg, S., & Amodei, D. (2017). [Deep Reinforcement Learning from Human Preferences](https://arxiv.org/abs/1706.03741).
[11] Liu, P., Qiu, X., & Huang, X. (2017). [Multi-Task Deep Neural Networks for Natural Language Understanding](https://arxiv.org/abs/1706.05137).
[12] Finn, C., Abbeel, P., & Levine, S. (2017). [Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks](https://arxiv.org/abs/1703.03400).
[13] Settles, B. (2010). [Active Learning Literature Survey](http://burrsettles.com/pub/settles.activelearning.pdf). University of Wisconsin-Madison.
[14] Hinton, G., Vinyals, O., & Dean, J. (2015). [Distilling the Knowledge in a Neural Network](https://arxiv.org/abs/1503.02531).
[15] Wei, J., Bosma, M., Zhao, V., Guu, K., Yu, A. W., Lester, B., … & Hernández, D. (2023). Many-Shot In-Context Learning. arXiv preprint arXiv:2304.11018.(https://arxiv.org/abs/2404.11018)
[16] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv preprint arXiv:2305.10601. https://arxiv.org/abs/2305.10601
[17] Besta, M., Blach, N., Kubíček, A., Gerstenberger, R., Podstawski, M., & Bojar, O. (2023). Graph of Thoughts: Solving Elaborate Problems with Large Language Models. arXiv preprint arXiv:2308.05276. https://arxiv.org/abs/2308.05276
[18] Chen, W., Lyu, X., Li, H., Liang, P., & Zhou, D. (2023). DSPy: Towards Domain-Specific Language Model Pre-training with Synthetic Programming Data. arXiv preprint arXiv:2304.06449. https://arxiv.org/abs/2304.06449
[19] Schick, T., & Schütze, H. (2020). Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based Bias in NLP. arXiv preprint arXiv:2005.04636. https://arxiv.org/abs/2005.04636
[20] Yao, S., Zhou, D., Schuurmans, D., Yu, J., & Li, H. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv preprint arXiv:2210.03629. https://arxiv.org/abs/2210.03629
